
STL六大部件
- 容器
- 分配器
- 算法
- 迭代器
- 适配器
- Functor

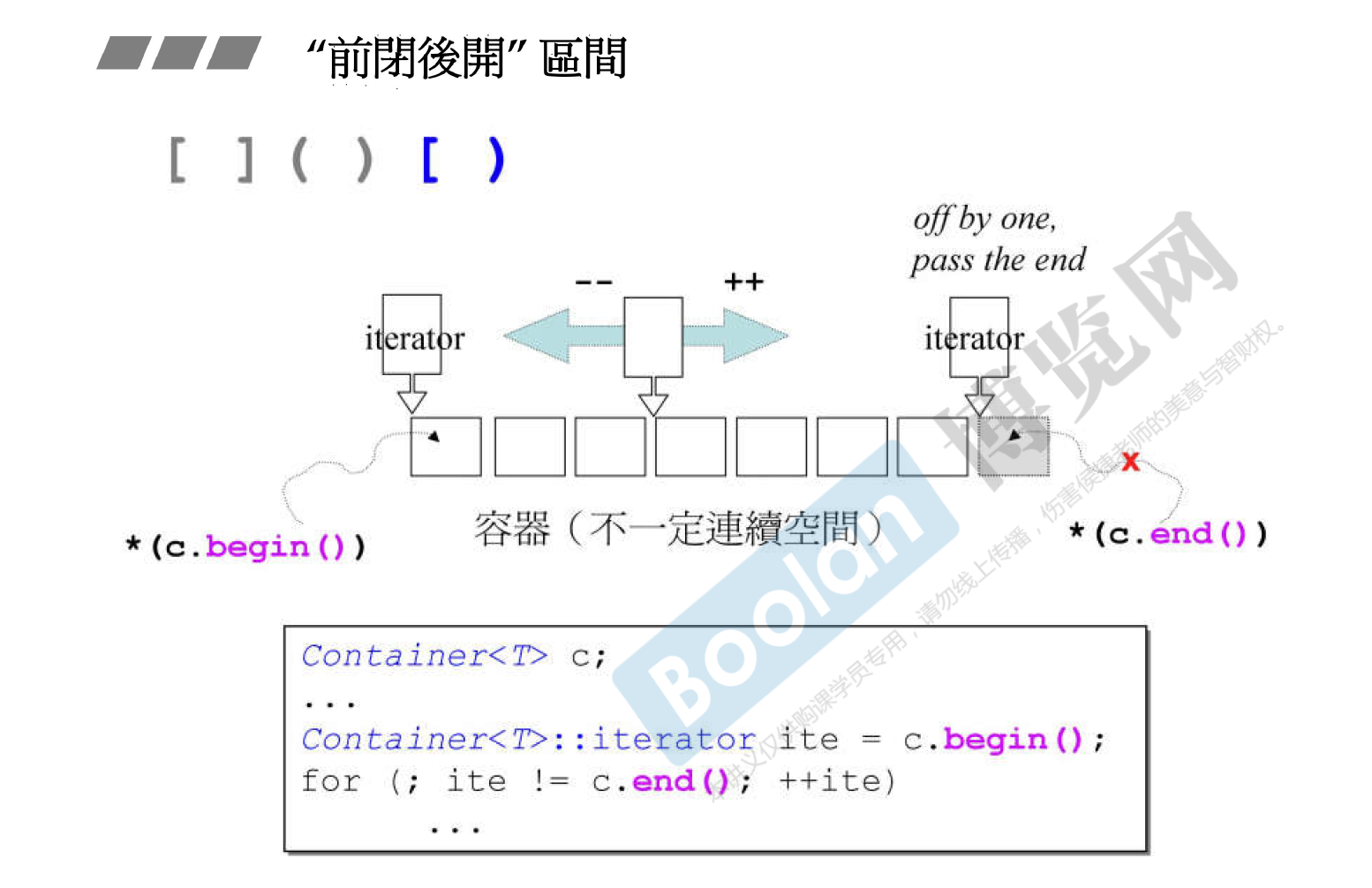
在STL容器中都是使用前闭后开区间
容器分类
- Sequence Containers
- Array
- Vector
- Deque
- List
- Associative Containers
- Set / Multiset
- Map / Multimap

分配器 allocators
alllocators中有**allocate()**分配内存时会调用new(), new()调用的是malloc()。
**deallocate()**会调用delete(), delete()会调用free().
迭代器 iterator
只要是连续空间迭代器就可以用指针来表示,需要Iterator Traits
顺序式容器
vector, list, deque
| 容器 | 说明 | 底层实现 |
|---|---|---|
| vector | 数组 | |
| list | 双向链表 | |
| deque | 中央控制器和多个缓冲区 |
顺序式容器中元素的位置是按照插入顺序排列的, 也就是容器自身没有排序功能, 顺序式容器都至少具有以下成员函数:
begin()
end()
rbegin()
rend()
front()
back()
erase()
clear()
push_back()
pop_back()
insert() // vector 和 deque 的 insert 复杂度较高vector
连续存储结果, 每个元素在内存上是连续的, 支持 高效的随机访问和尾端插入/删除操作, 但其他位置的插入/删除操作效率低下, 可以看做是一个数组, 但是与数组的区别为: 内存空间的扩展. vector 支持动态大小的数据存储, 而数组则必须指定大小, 但需要扩展空间时, 需要手动实现.

vector的内存分配原理及实现: 在STL内部实现时, 首先分配一个较大的内存空间预备存储, 即capacity()函数返回的大小, 当超过此分配的空间时, 会再重新分配一块更大的内存空间(VS6.0是两倍, VS2005是1.5倍). 通常默认的内存分配能完成大部分情况下的存储操作. 扩展空间的步骤:
- 配置一块新空间
- 将就元素一一移动到新地址中
- 把原来的空间释放掉
vector的数据安排以及操作方式, 与数组模板Array十分相似, 两者唯一的差别在于空间利用的灵活性, Array的空间扩展需要手动实现
头文件:
#include <vector>声明及初始化:
vector<int> vec; // 声明一个空的vector
vector<int> vec(5);
vector<int> vec(10, 1); // 大小为10, 初始值为1
vector<int> vec(oldVec);
vector<int> vec(oldVec.begin(), dolVec.begin()+3);
int arr[5] = {1, 2, 3, 4, 5};
vector<int> vec(arr, arr+5); // 用数组初始化vec
vector<int> vec(&arr[0], &arr[5]); // 用数组初始化vec, 注意这里是超尾, 与end相对应注意: push_back和emplace_back并不等价, 例如, 如果 vector 中存储的是一个 pair 类型的数据, 那么在添加新元素时, 存在以下区别:
std::vector<std::pair<int, int>> vec;
vec.push_back(std::make_pair(1, 2)); // 合法
vec.push_back({1, 2}); // 合法
vec.emplace_back(std::make_pair(1, 2)); // 合法
vec.emplace_back({1, 2}); // 不合法!!!!vector 的内存分配机制是怎样的?
vector 是一个动态数组, 里面由一个指针值指向一片连续的内存空间, 当空间不够装下数据时, 就会自动申请一片更大的空间, 然后把原有数据拷贝过去, 接着释放原来的那片空间. 不同的编译器实现的扩容方式不一样, 有的是 1.5 倍, 有的是 2 倍(GCC). 初始时刻的capacity为 0.
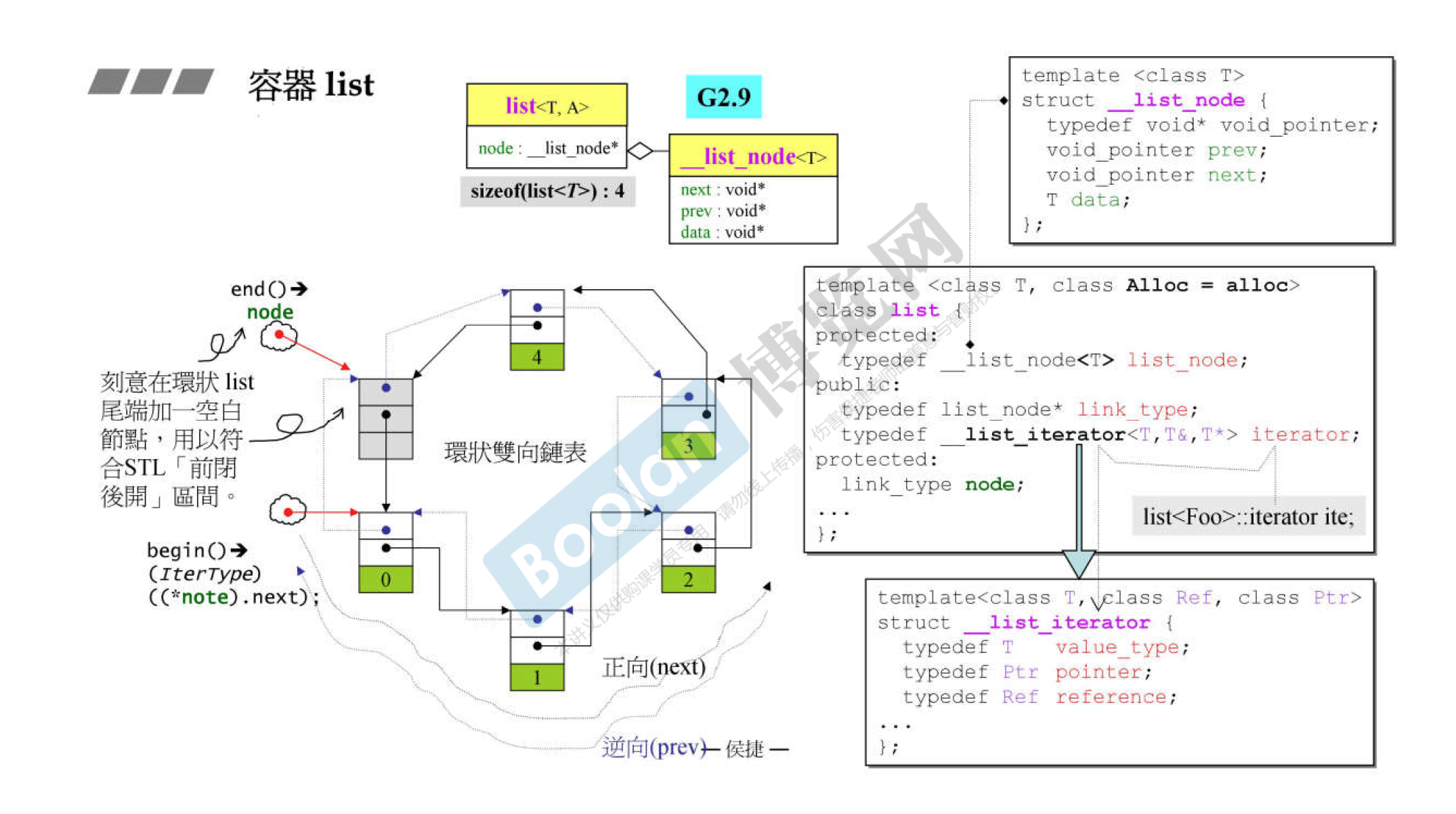
list
非连续存储结构, 具有双向链表结构, 每个元素维护一对前向和后向指针, 因此支持前向/后向遍历. 支持高效的随机插入/删除操作, 但是随机访问效率低下, 且由于需要额外维护指针, 开销也比较大. 每一个节点都包括一个信息块info, 一个前驱指针Pre, 一个后驱指针Post.
优点:
- 不使用连续内存完成插入和删除操作, 使得能够在常数时间内插入新元素
- 在内部方便的进行插入和删除操作
- 可以在两端 push, pop
缺点:
- 不能进行随机访问, 即不支持
[]操作符和.at()访问函数 - 相对于 vector 占用内存多
list与vector的区别
- vector 为存储的对象分配一块连续的地址空间, 随机访问效率很高. 但是插入和删除需要移动大量的数据, 效率较低. 尤其当vector内部元素较复杂, 需要调用复制构造函数时, 效率更低.
- list 中的对象是离散的, 随机访问需要遍历整个链表, 访问效率比 vector 低, 但是在 list 中插入元素, 尤其在首尾插入时, 效率很高.
- vector 是 单向的 的, 而 list 是双向的 (vector为什么单向???)
- vector 中的 iterator 在使用后就释放了, 但是 list 不同, 它的迭代器在使用后还可以继续使用, 是链表所特有的.
头文件:
#include <list>声明和初始化:
list<int> l;
list<int> l(5); // 含有5个元素的list, 初始值为0
list<int> l(10, 1); // 含有10个元素的list, 初始值为1
list<int> l(oldL); // 复制构造
list<int> l(oldL.begin(), oldL.end());
int arr[5] = {1, 2, 3, 4, 5};
list<int> l(arr, arr+5); // 用数组初始化list
list<int> l(&arr[1], &arr[5]); // 用数组初始化list常用函数:
list.merge() // 合并两个list
list.remove()
list.remove_if() // 按指定条件删除元素
list.reverse() // 逆置list元素
list.sort() // 排序
list.unique() // 删除重复元素
list.splice() // 从另一个 list 中移动元素
push_front() // vector 没有该函数
pop_front() // vector 没有该函数deque
双端队列: double-end queue 连续存储元素, 即每个元素在内存上是连续的(假象,实际不是连续的,只是给使用者的感觉是连续的), 类似于vector, 不同之处在于, deque提供了两级数组结构, 第一级完全类似于vector, 代表实际容器, 另一级维护容器的首位地址, 这样, deque除了具有vector的所有功能之外, 还支持高效的首/尾端的插入/删除操作.
连续内存的容器有个明显的缺点, 就是在插入新元素或删除老元素时, 有时需要进行移动, 代价很大, 而 deque 实际上是分配到不同的内存块, 通过链表把内存块连载一起, 再进行连续存放, 是 list 与 vector 的折衷.


优点:
- 随机访问方便, 支持
[]操作符和.at()访问函数, 常数时间, 次于 vector, 因为有可能存在尾部的内存位置在头部之前的场景. - 可在两端进行push, pop操作, 效率都较高.
缺点: 占用内存多
头文件
#include <deque>常用函数:
push_back()
pop_back()
push_front() // vector 没有该函数
pop_front() // vector 没有该函数
queue不可选择vector作为底层结构(pop()会出问题,vector没有pop_front());stack可以选择vector作为底层结构;queue和stack都不可选择set或者map作底层结构
关联式容器
map, unordered_map, multimap, unordered_multimap set, unordered_set, multiset, unordered_multiset
| 容器 | 说明 | 底层实现 | 操作复杂度 |
|---|---|---|---|
| map | 键值对的映射, 有序, 元素不可重复 | 红黑树 | O(logn)) |
| unordered_map | 键值对的映射, 无序, 元素不可重复 | 哈希表 | O(1) |
| multimap | 键值对的映射, 有序, 元素可重复 | 红黑树 | O(logn) |
| unordered_multimap | 键值对的映射, 无序, 元素可重复 | 哈希表 | O(1) |
| set | 关键字集合, 有序, 元素不可重复 | 红黑树 | O(logn) |
| unordered_set | 关键字集合, 无序, 元素不可重复 | 哈希表 | O(1) |
| multiset | 关键字集合, 有序, 元素可重复 | 红黑树 | O(logn) |
| unordered_multiset | 关键字集合, 无序, 元素可重复 | 哈希表 | O(1) |
红黑树 rb_tree

hashtable

如果总的元素个数已经超过了buckets的大小,那么这个哈希表就buckets设为原来的两倍,重新hash放入。
buckets大小通常是素数。
map
简介
map 提供键值对的映射关系, 相当于 字典, 其中, 每个关键字只能出现一次, map 底层采用红黑树实现, 会按照给定的排序规则进行排序, 在 map 上进行的搜索, 插入和移除等操作都具有 对数复杂度.


找到了就返回,没找到就插入进去
头文件
#include <map>常用操作(以下操作复杂度均为对数复杂度)
// 数据插入, 复杂度为 logn
map.insert({key, value});
map[key] = value;
// 移除, 复杂度为 logn
map.erase(key)
// 搜索, 复杂度为 logn
map.find()
map[key]
map.count() // 返回匹配特定键的元素数量, 对数复杂度
map.contains()
map.equal_range()
map.lower_bound()
map.upper_bound()unordered_map
简介
map 提供键值对的映射关系, 相当于 字典, 其中, 每个关键字只能出现一次, unordered_map 底层采用哈希表实现, 容器中的元素是无序的, 在容器上进行的搜索, 插入和移除等操作都拥有平均常数时间复杂度.
头文件
#include <unordered_map>常用操作(以下操作复杂度平均情况下均为常数)
// 数据插入
unordered_map[key] = value;
// 移除
unordered_map.erase(key)
// 搜索
unordered_map.find()
unordered_map[key]
unordered_map.count() // 返回匹配特定键的元素数量
unordered_map.contains()
unordered_map.equal_range() // 复杂度平均情况下与带有关键字的元素数呈线性
// 桶接口
bucket_count() // 返回桶数
max_bucket_count() // 返回桶的最大数量
bucket_size() // 返回在特定的桶中的元素数量
bucket() // 返回带有特定键的桶键的类型
默认情况下, unordered_map 只支持将基本类型作为 key, 如下面的代码是不合法的:
unordered_map<pair<int, int>, int> hash;而map可以使用pair类型作为key.
关于 hash_map
C++中的hash_map是标准模板库(STL)的一部分, 但是它不是标准库(Standard Library)的一部分. 有很多编译器(GNU, VS)的实现都提供了这个数据结构. C++11标准库引入了unordered_map, 其功能和hash_map相同.
与map的区别 在STL中, map对应的数据结构是红黑树, 红黑树是一种近似于平衡的二叉查找树, 里面的数据是有序的, 在红黑树上做查找的时间为 O(lonN). 而unordered_map对应哈希表, 哈希表的特点就是查找效率高, 时间复杂度基本为 O(1) , 而额外空间复杂度较高.
multimap
简介
multimap 提供键值对的映射关系, 相当于 字典, 其中, 每个关键字可以出现多次, multimap 底层采用红黑树实现, 会按照给定的排序规则进行排序, 拥有等价关键字的键值对的顺序就是插入时的顺序, 且不会发生更改. 在 multimap 上进行的搜索, 插入和移除等操作都具有 对数复杂度.
头文件
#include <map>常用操作(以下操作复杂度均为对数复杂度)
// 数据插入, 复杂度为 logn
multimap.insert({key, value});
// 移除, 复杂度为 logn
multimap.erase(key)
// 搜索, 复杂度为 logn
multimap.find() // 寻找指定关键字对应的元素, 如果容器中存在多个满足条件的元素, 则可能会返回任意一者
multimap[key] // 不支持!!
multimap.count() // 返回匹配特定键的元素数量, 对数复杂度
multimap.contains()
multimap.equal_range()
multimap.lower_bound() // 有序 map 所独有的
multimap.upper_bound()注意, multimap 不支持使用 [] 和 at() 对来访问关键字对应的 value, find() 查找到的元素迭代器可能是满足条件的任意一个元素
unordered_multimap
简介
map 提供键值对的映射关系, 相当于 字典, 其中, 每个关键字可以出现多次, unordered_multimap 底层采用哈希表实现, 容器中的元素是 无序 的, 在容器上进行的搜索, 插入和移除等操作都拥有平均常数时间复杂度.
头文件
#include <unordered_multimap>常用操作(以下操作复杂度平均情况下均为常数)
// 数据插入
unordered_multimap.insert() // 不支持 [] 或者 at 访问
// 移除
unordered_multimap.erase(key)
// 搜索
unordered_multimap.find()
unordered_multimap.count() // 返回匹配特定键的元素数量
unordered_multimap.contains()
unordered_multimap.equal_range() // 复杂度平均情况下与带有关键字的元素数呈线性
// 桶接口
bucket_count() // 返回桶数
max_bucket_count() // 返回桶的最大数量
bucket_size() // 返回在特定的桶中的元素数量
bucket() // 返回带有特定键的桶注意, unordered_multimap 不支持使用 [] 和 at() 对来访问关键字对应的 value, find() 查找到的元素迭代器可能是满足条件的任意一个元素
set
简介 set 是一个关键字集合, 其中的关键字 不可重复, 其底层采用红黑树实现, 因此集合中的元素是 有序 的, 在 set 容器上进行的搜索, 插入和移除等操作都是 对数复杂度 的.

特有操作
lower_bound() // 返回指向首个不小于给定键的元素的迭代器
upper_bound() // 返回指向首个大于给定键的元素的迭代器
erase_if()unordered_set
简介
set 是一个关键字集合, 其中的关键字 不可重复, 其底层采用哈希表实现, 因此集合中的元素是 无序 的, 在 unordered_set 容器上进行的搜索, 插入和移除等操作都是 常数复杂度 的.
基本用法
unordered_set<string> stringSet;
stringSet.insert("code");
stringSet.insert("fast");
string key1 = "fast";
stringSet.find(key1); // return iter, 指向 fast
string key2 = "slow"
stringSet.find(key2); // return stringSet.end()
vector<int> nums {1,2,3,4,5,6,7,8,9};
unordered_set<int> sets(nums.begin(), nums.end())
int key;
sets.count(key); // 返回拥有关键key的元素个数, 即只会返回1或0.multiset
简介
multiset 是一个关键字集合, 其中的关键字 可以重复, 其底层采用红黑树实现, 因此集合中的元素是 有序 的, 在 multiset 容器上进行的搜索, 插入和移除等操作都是 对数复杂度 的.
注意, 迭代器不能进行算数运算, 即不能 multiset.end() - multiset.begin(). 如果要计算两个迭代器之间的元素数目, 应该用 std::distance(multiset.begin(), multiset.end()), 同时, 要注意, 第一个元素必须小于第二个元素, 在vector中, 可以返回负值距离, 但是在multiset中, 不会返回负值距离, 程序会一直循环直到溢出.
unordered_multiset
简介 set 是一个关键字集合, 其中的关键字 可以重复, 其底层采用哈希表实现, 因此集合中的元素是 无序 的, 在 unordered_set 容器上进行的搜索, 插入和移除等操作都是 常数复杂度 的.
迭代器

容器适配器
stack
queue
priority_queue
堆中元素相同时, 先来的会先输出
大顶堆
默认比较函数为less, 对应为大顶堆
priority_queue<int> q;小顶堆
使用比较函数greater, 对应为小顶堆
复制
priority_queue<int, vector<int>, greater<int>> q;
// pair 自身重载的比较运算符, 默认按字典序比较pair中的值
// 首先比较 first 的大小, 当 first 大小相同时, 比较 second 的大小
priority_queue<pair<int, int>, vector<pair<int, int>>,
greater<pair<int, int>> > min_heap;自定义类型和排序方法
优先出列时会对 !cmp 判定, 所以如果希望小的在前(小顶堆), 那么就应该返回 元素1 > 元素2. 注意, 不能在排序方法中写 <=, 或者 >= 等包含 = 的情况.
复制
#include <vector>
#include <string>
#include <queue>
#include <iostream>
int main() {
// 仿函数自定义比较
struct cmp {
bool operator()(const std::pair<int, std::string> &p1,
const std::pair<int, std::string> &p2) {
return p1.first > p2.first;
}
};
std::priority_queue< std::pair<int, std::string>,
std::vector<std::pair<int, std::string>>,
cmp
> min_heap_fun;
min_heap_fun.push({1, "abc"});
min_heap_fun.push({2, "def"});
std::cout << min_heap_fun.top().second << std::endl;
// lambda 自定义比较
auto lamCmp = [](const std::pair<int, std::string> &p1,
const std::pair<int, std::string> &p2) {
return p1.first > p2.first;
};
std::priority_queue< std::pair<int, std::string>,
std::vector<std::pair<int, std::string>>,
decltype(lamCmp)
> min_heap_lam(lamCmp);
min_heap_lam.push({1, "abc"});
min_heap_lam.push({2, "def"});
std::cout << min_heap_lam.top().second << std::endl;
return 0;
}复制
struct cmp{
bool operator()(ListNode * node1, ListNode * node2){
return node1->val > node2->val;
}
};
priority_queue<ListNode *, vector<ListNode *>, cmp> min_heap;算法
【链接】C++STL一般总结 http://www.cnblogs.com/biyeymyhjob/archive/2012/07/22/2603525.html
sort()
注意, sort 传入的比较函数和 priority_queue 的比较类是不同的, 前者传入的是 Compare 类型的对象(实际上是传入了二元函数, 这里的函数对象重载了()运算符), 后者传入的是 Compare 类型. 也因此, 二者在使用 lambda 表达式上也存在区别.
复制
partial_sort()
nth_element()
nth_element算法将重新排列区间[first, last)的序列元素, 算法执行完毕后, 会使得
- 第 k� 个位置的元素在最终的算法执行完毕后, 和整个区间完全排序后该位置的元素相同.
- 这个新的
nth元素之前的所有元素均 <= (>=)nth元素之后的所有元素. 但是该算法并不保证位于第 k� 个元素两边区间的元素有序. 该算法和partial_sort算法之间一个很大的区别在于:nth_element对于除第 k� 位置的元素之外的区间元素的顺序不做保证, 而partial_sort排序后会使得前 m� 个数的子区间是有序的. 正因为如此, 在需要无序的前top_k个值时,nth_element相对于partial_sort要更快.(只需要找第 k� 个值, 其前面的元素即为 top_k, 时间复杂度为 O(n)�(�)).
假如有序列
复制
int v[10]={41,67,34,0,69,24,78,58,62,64};我们用nth_element求第5小的元素, 则可以执行
复制
std::nth_element(v, v+4, v+10);若使用的是模板vector, 则可执行:
复制
vector <int> v = {41,67,34,0,69,24,78,58,62,64};
std::nth_element(v.begin(), v.begin()+4, v.end());算法执行完毕后, 第5小的元素便是v[4] = 58. 并且, 所有比58小的元素都在v[4]的左边, 大于等于58的都在v[4]的右边.(v[4]在相同元素中排在最前面)
nth_element默认时按照从小到大排序, 如果希望找到第 k� 大的元素, 则应该传入相应的仿函数:
复制
std::nth_element(v.begin(), v.begin()+4, v.end(), std::greater<int>());nth_element的算法原理: 基于 Partition
- 从给定的区间[first, last)中使用三点取值法获取一个枢纽值(三点中值)
pivot. - 将小于
pivot的元素调整至左边区间, 将大于等于pivot的元素调整至右边区间 - 判断
nth的位置是处在左边的区间还是右边的区间, 然后对nth所在的区间重复进行上述操作, 直到该区间的元素数小于等于3. - 经过上面的操作, 此时的区间元素数小于等于3, 对该区间进行一次全排列, 以固定nth所处位置的元素.
复杂度分析: 基于 Partition , 查找第 k� 大/小的元素, 其复杂度为 O(n)�(�). 因为当我们找到第一个 Partition 的结果pivot时, 只有三种可能:
pivot的位置就是nth, 则程序结束, 可返回结果pivot的位置在nth的右边, 则说明nth在pivot的左边, 因此需要在左边的范围内继续调用 Partitionpivot的位置在nth的左边, 则说明nth在pivot的右边, 因此需要在右边的范围内继续调用 Partition
可以看出, 基于 Partition 的查找第 k� 大/小元素的算法, 与快排的一个明显区别就是: 每一次 Partition 之后, nth_element 算法只需要再对两边中的其中一边调用 Partition 即可, 而快排则需要同时对两边都调用 Partition. 鉴于 Partition 的复杂度为 O(n)�(�), 则快排因为要进行 logn���� 次 Partition, 所以快排的时间复杂度就是 nlogn�����.(T(n)=2×T(n/2)+O(n)�(�)=2×�(�/2)+�(�)) 而 nth_element 的时间复杂度为 T(n)=T(n/2)+O(n)=O(n)+O(n/2)+O(n/4)+…�(�)=�(�/2)+�(�)=�(�)+�(�/2)+�(�/4)+…, 也就是 O(n)�(�).
源码剖析:
binary_search()
upper_bound()
lower_bound()
next_permutation()
prev_permutation()
is_permutation()
find()
标准库中各个容器的数据结构是什么?
vector 的容量增长机制是怎样的? 内存分配机制是怎样的?
为什么vector::push_back()的复杂度是分摊之后的 O(1)�(1)?
设计一道可以使用low_bound/upper_bound轻松解决的算法题
对于一个已排序的数组, 统计指定元素的个数
实现一下set_intersection()/set_union()/merge()
迭代器在什么情况下会失效?
标准库的线程安全性
list 的insert()/erase()与 vector 相比哪个快?
对于百万量级以上的数据, list 的插入和删除比 vector 快很多. 但是对于容器大小为十万量级的数据, 从前端一次删除所有元素, vector 需要 3 s 左右, 而 list 需要 8s, list 更慢.
- 这篇博客对比了在list、vector、deque上进行不同操作的效率差别。C++ benchmark作者在文章最后给出了源码:articles/bench.cpp at master · wichtounet/articles · GitHub
- 这一篇更是颠覆我的三观(待会儿做个测试)http://blog.davidecoppola.com/2014/05/20/cpp-benchmarks-vector-vs-list-vs-deque/C++之父动情地抓着记者的手,说:I hate linked list。 . C++ STL containers: what’s the difference between deque and list?