引言
预编译->编译->汇编->二进制可重定位目标文件
链接
编译链接过程

⭐在编译过程中,源文件经过预编译、编译和汇编的过程,生成了二进制的可重定位的目标文件;
⭐此后,在链接过程,所有.o文件对应的段进行合并,其中symtab就是符号表段,符号表进行合并后,需要对符号进行解析
⭐对符号进行解析:所有对符号的引用,都要找到其定义的地方
示例如下:
#include<bits/stdc++.h>
#include<iostream>
extern int gdata;
int sum(int,int);
int main(){
//省略
}在上面的main.cpp文件中引用了外部文件的变量gdata以及函数sum,所以main.o文件中gdata和sum属于UND类型,也就是未定义;所以在链接的时候就需要找到其定义的地方,也就是对符号进行解析;
⭐对符号进行解析完成后,就会给所有的符号分配虚拟地址;
⭐符号重定位:就是将给符号分配后的地址写回代码段;
注意:符号并不是在编译过程中分配虚拟地址的,而是在链接过程分配虚拟地址的,更具体一点就是在符号解析完成后进行分配的。
预编译(Prepressing)
预编译过程主要处理那些源代码文件中#开头的预编译指令: 例如:#include<XXX>、#define XXX、#ifdef XXX等; 预编译过程相当于如下命令:
gcc -E main.c -o main.i主要规则如下:
将所有的"#define"删除,并且展开所有的宏定义;
处理所有条件预编译指令,比如"#if"、"#ifdef"、"#elif"、"#else"、"#endif";
处理"#include"预编译指令,将被包含的文件插入到该预编译指令的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件;
删除所有的注释:"//" 和 “/**/”;
添加行号和文件名标识,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号;
保留所有的 “#pragma” 编译器指令,因为编译器要使用它们。 注: #pragma lib、pragma link等命令是在链接过程处理的。
预编译后得到的文件为:.i文件。
编译(Compilation)
编译的过程就是把预编译后得到的.i文件进行一系列==词法分析、语法分析==、以及==优化==,随后生产相应的汇编代码文件。 上面的编译过程相当于如下命令:
gcc -S main.i -o main.s编译后得到的文件为:.s文件。
汇编(Assembly)
汇编是将汇编代码转变为机器可以执行的指令的过程:汇编代码 -> 指令; 上面的汇编过程我们可以调用汇编器as来完成:
as main.s -o main.o 或者: gcc -c main.s -o mian.o
汇编完成后得到二进制可重定位目标文件:.o文件。 我们可以通过objdump命令来查看.o或者.exe文件的相关信息; 例如:objdump -t main.o来查看main.o里面的符号表信息:
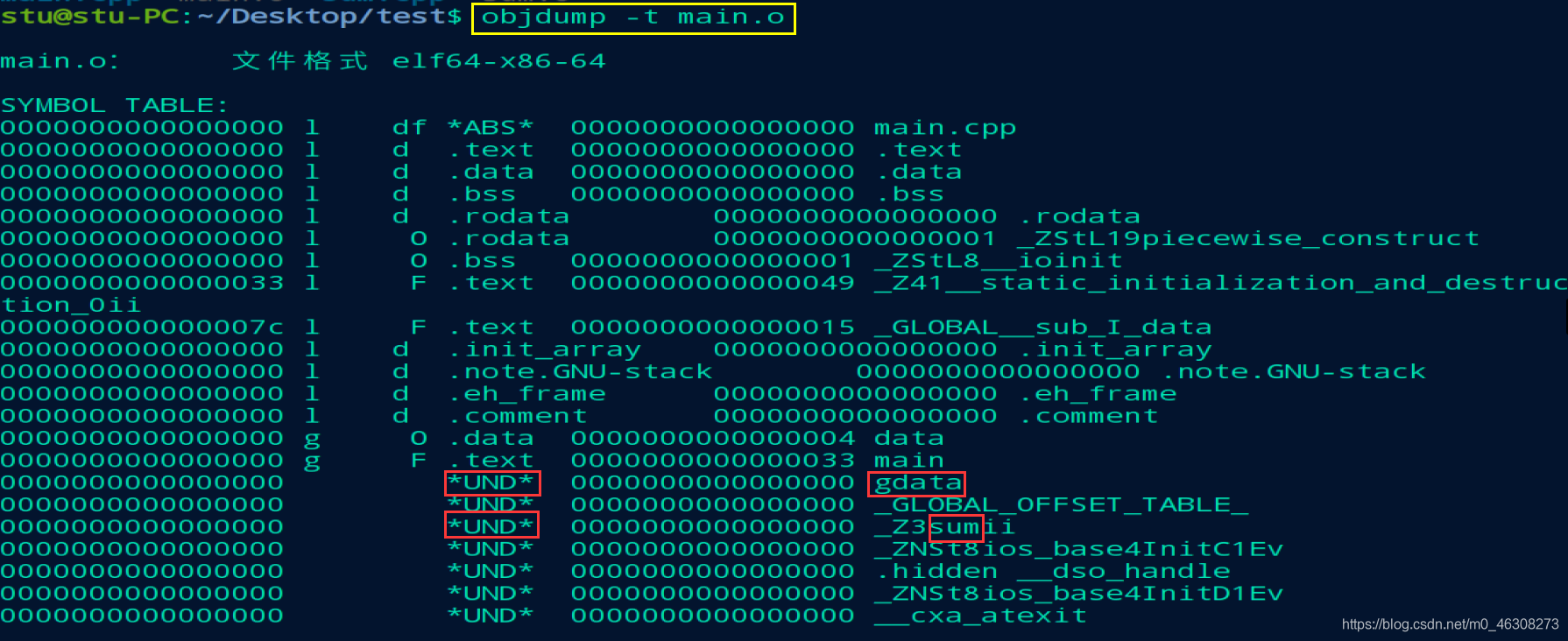
我们可以看到在
main.o里面引用了外部文件的gdata变量和sum函数,在符号表中都是UND的,也就是(undefine); 这就意味着汇编器生成符号的时候在main.cpp文件中使用到了但是未找到gdata和sum的定义,所以只能暂时存放在UND段中。l: local; g:global ; 只有global的才能链接时候在其他文件可以看见
其次,我们会注意到,符号表中关于sum的部分是_Z3sumii,其实这就是C++生成符号的规则,具体细节我们不用去深究,但是可以看到其中包含了函数名和形参列表,这也是C++和C语言不一样的地方,如果我们相同的代码使用C语言来看看符号表,就会发现长这样:
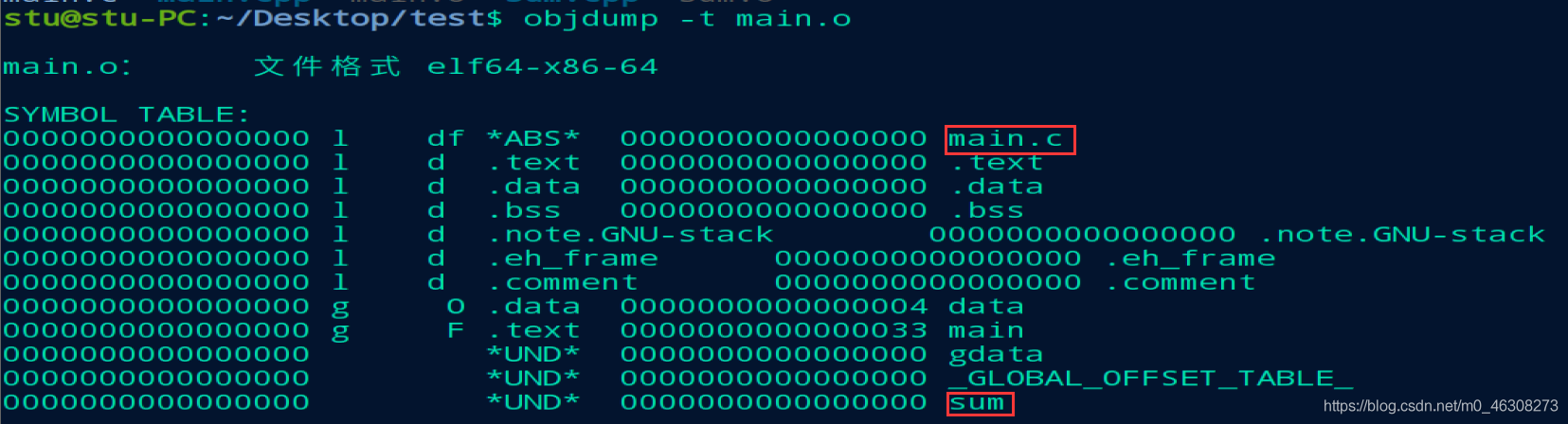
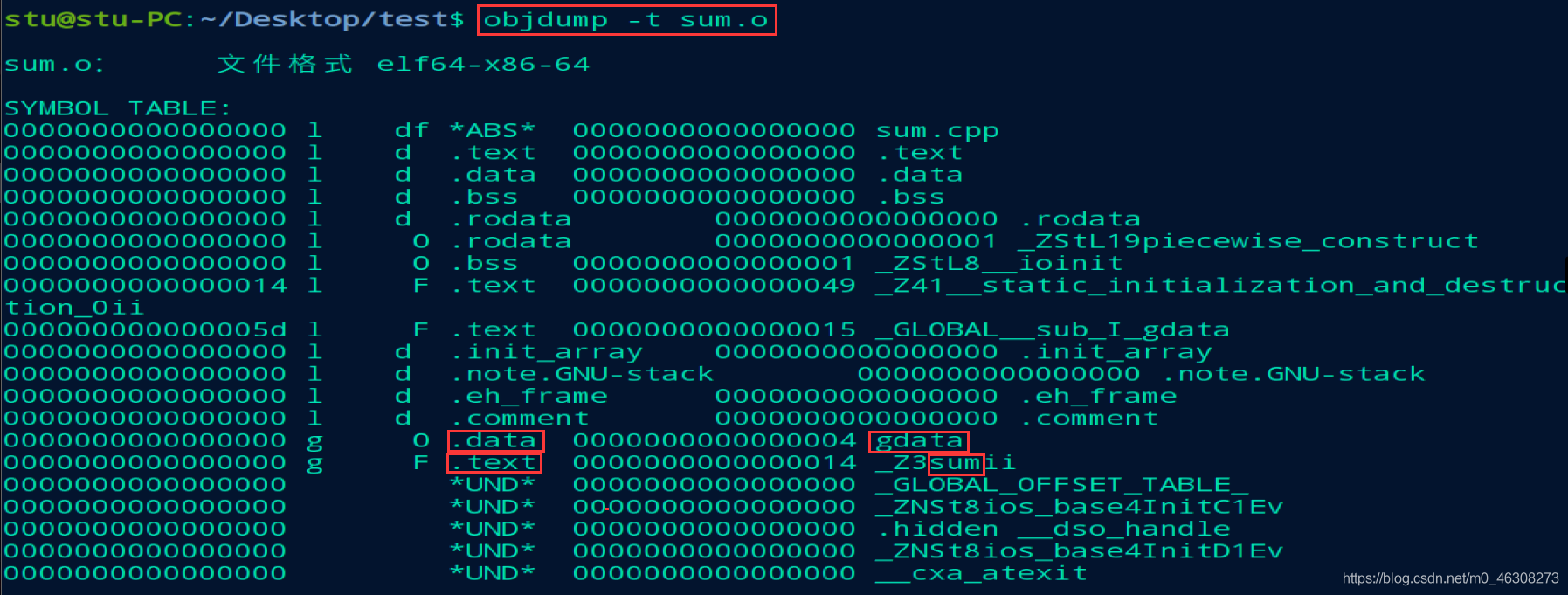
同理objdump -t sum.o来查看sum.o里面的符号表信息:
链接过程(Linking)
链接:编译完成的所有.o文件+.a / .lib文件。
步骤一: 所有
.o文件段的合并,符号表合并后,进行符号解析; 步骤二: 符号的重定位(重定向)。
首先是所有.o文件段的合并, 也就是main.o和sum.o的.text、.data等段合并到一起。 其次是符号解析,可以理解为:
所有对符合引用,都要找到该符号定义的地方 也就是链接器寻找main.o文件中*UND*的gdata和sum符号定义的地方,如果找遍了所有地方都没有找到,那么链接器就会报错:符号未定义!,或者是在多个地方都找到了相同的符号定义,那么也会报错:`符号重定义!
对于本例来说,这两个符号会在sum.o的.text和.data段找到符号的定义地方。 最后是符号的重定向: 给所有的符号分配虚拟地址,之后去代码段中给所有的符号重定向。 通过objdump -S main.o我们可以发现:
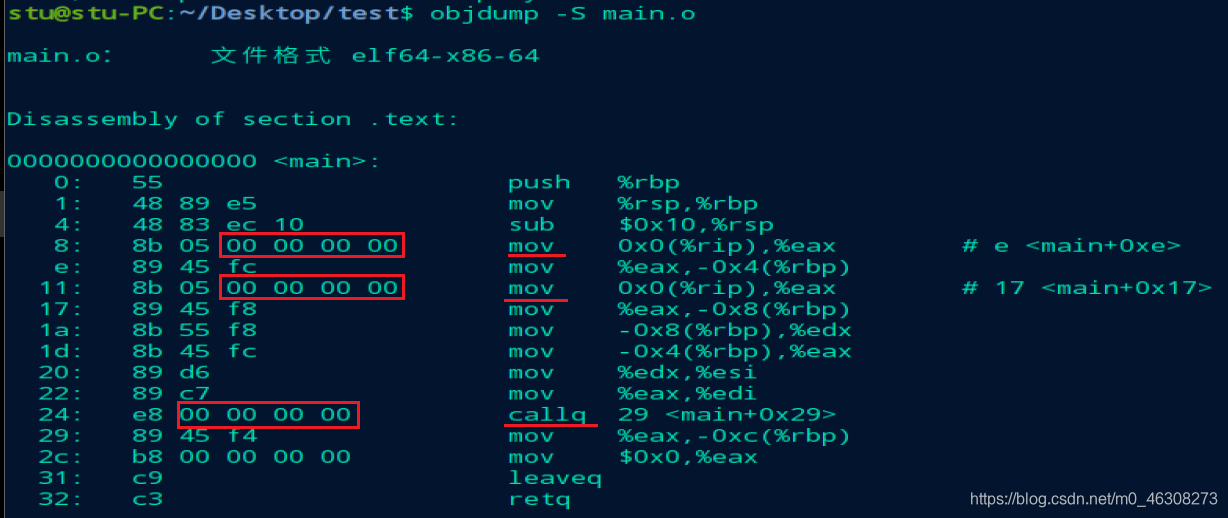
在汇编器生成符号的时候,并未给符号分配虚拟地址,所有在汇编代码上填充的都是00 00 00 00; 那么在符号解析完成后,给所有符号分配完虚拟地址后,还需要做一件重要的事情:去代码段.text将之前填充的00 00 00 00修改为该符号正确的地址。 待到链接完成后,我们再去通过相同的指令去查看objdump -S a.out:
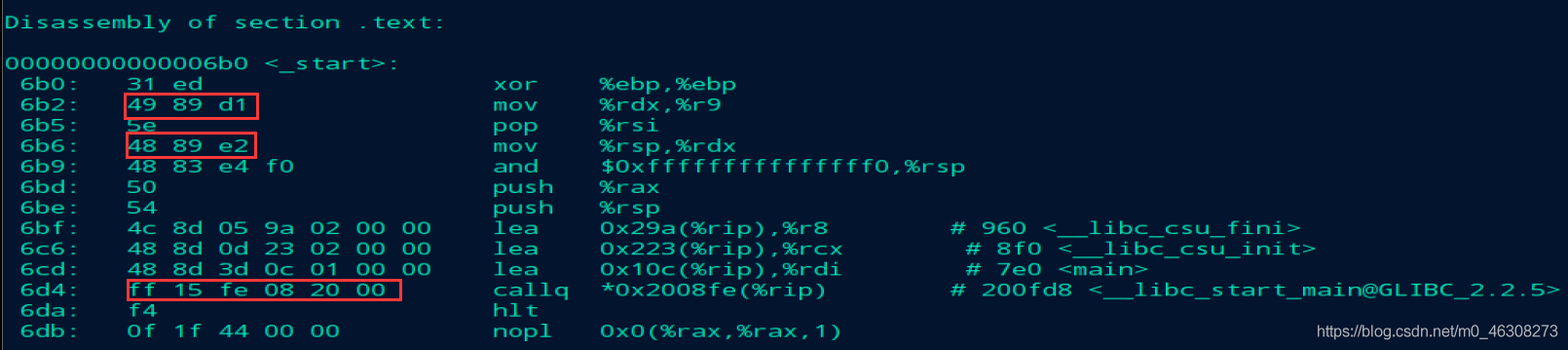
可以看到此时经过符号重定位后,代码段的具体地址已经被重定位为新的地址了。
==符号什么时候分配虚拟地址?----- 在链接第一步, 符号解析完成后!==
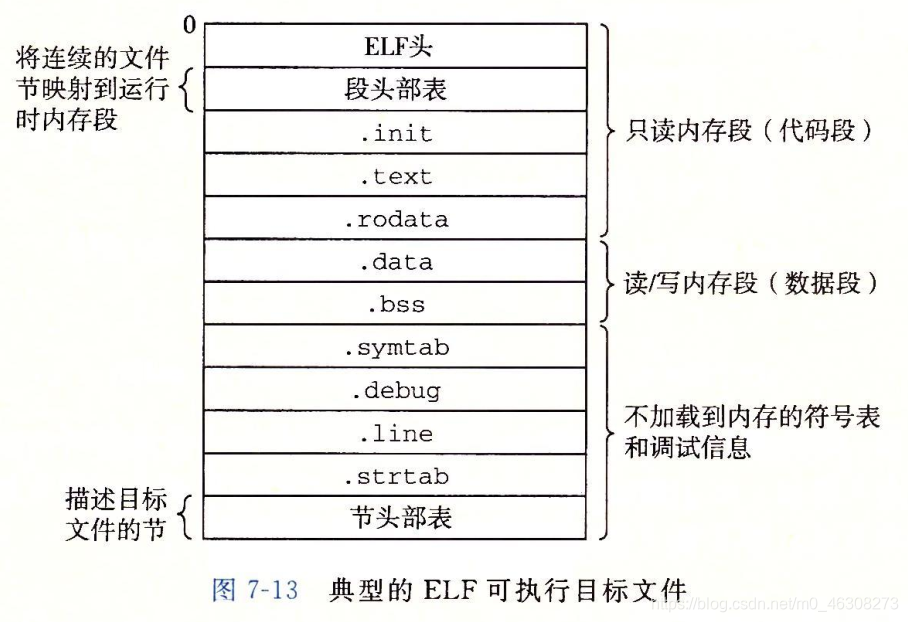
.out 可执行文件和 .o 文件都是由各种段组成,但是a.out 有一个 program 段,这个里面有两个load,告诉系统运行这个程序的时候,把哪些内容加载到内存当中!!!

面试题
为什么目标文件(.obj)不能运行? 首先编译阶段不会分配虚拟地址,通过
objdump -S main.o指令我们可以看到反汇编下的代码:
我们可以发现,在引用外部变量及函数的时候,==汇编指令的地址都是
00 00 00 00==,这个地址是不可访问区,这也就意味着,如果不进行链接的话,仅通过目标文件,机器根本无法正常执行指令。
从这个角度来看,目标文件是无法运行的。(原因之一)
符号什么时候分配虚拟地址? 在链接过程,具体是在符号解析完成后,会给所有的符号分配虚拟地址。
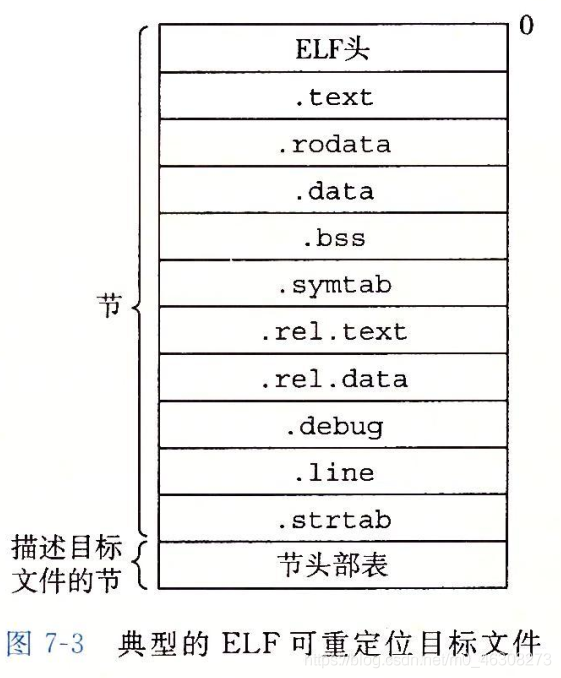
目标文件(.o)的格式组成?
可执行文件(.exe)的格式组成?